2020/07/29 - [공부/강화학습] - Reinforcement Learning, Open AI GYM
(이전에 공부한 Q table)
<Q network>
state가 많은 환경에서는 Q-Table을 사용하기 어렵다. 이때 Q Learning에도 Deep Learning처럼 network를 적용할 수 있다. 일반적인 neural network에는 input, output layer가 있고 loss function을 정의하고 최적화하는 과정을 포함한다. loss function은 min sum square(WX - Y)의 형태이다. Q network도 이와 같은 방식으로 구현한다.
Q network에서 input은 state, output은 action이다. 그리고 Q network에서의 WX는 Q-prediction(예측값)인 Ws이다. X는 state input(one-hot encoding 등의 전처리를 거친 데이터)이고, W는 network에서 학습되면서 update 되는 random weight이다. Y는 target, label로서 Q-optimal(실제값)이다. Y 값은 terminal state인 경우(done)에는 reward r이 되고, 진행 중인 경우에는 r + dis * max Q(s' , a')이 된다. Q-optimal과 loss function은 아래와 같다.
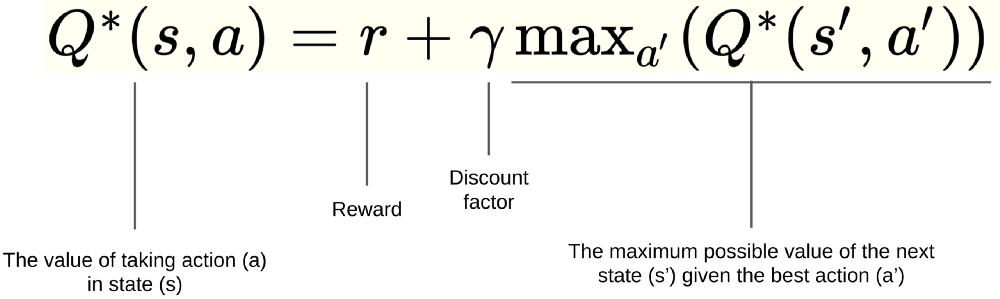
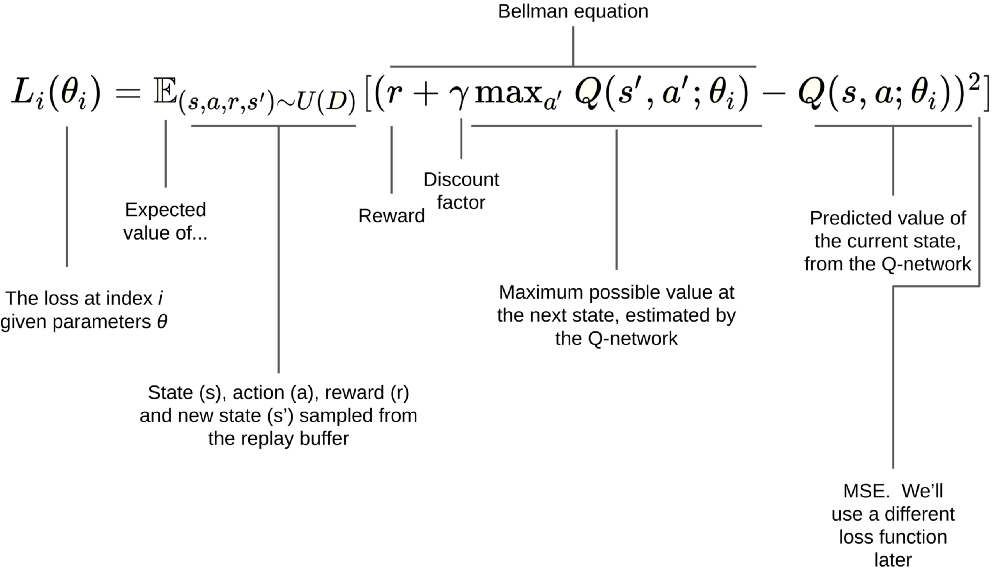
전체적인 알고리즘 구현은 다음과 같다. 입력 데이터 S를 받고 W를 초기화한다. 그리고 S와 W를 행렬곱으로 하여 Q-prediction인 Ws를 구한다. 다음으로 optimizer를 달고 loss function을 정의하며 train fitting을 한다. 실제로 학습이 진행되는 과정은 아래와 같다.

학습 과정에서 Q network는 episode를 진행하면서 network에서 state를 얻는다. 그리고 전에 공부한 Decaying E-greedy 등의 방법으로 action을 선택한다. environment에서 action을 수행해서 reward, next state, done 등의 값을 받고 state를 변경한다. 이 값들과 Bellman equation을 이용하여 target Y 값을 구한다. 실제 코드에서는 위에서 optimizer를 달고 loss function을 정의했기 때문에 여기서 값이 넘어가면서 gradient descent가 진행되고 학습이 이루어진다.
<DQN>
하지만 위의 단순한 Q network로 게임을 해보면 정확도가 매우 낮다. 그 이유는 연속적인 환경에서 sample을 받을 때 상당히 유사하고 연관성이 크다는 문제, network weight을 update 하는 동안 target이 움직이는 문제 때문에 network의 prediction이 target에 가까워지지 않고 diverges 된다. Deep mind 팀이 공개한 DQN Algorithm은 이 문제에 대한 해결법을 포함한다.
우선 correlations between sample 은 sample이 서로 가깝고 연관성이 크다면, 비슷한 데이터만 가지고 linear regression을 하는 것과 마찬가지로 network의 weight을 잡기가 어렵고 정확도가 떨어진다. 이 문제는 capture and replay 방법으로 간단하게 해결할 수 있다. action을 수행하고 바로 학습을 하는 것이 아니라, action으로 얻는 state, reward 등을 buffer에 일단 저장(capture)하고 나중에 random 하게 사용하는 방식이다. 이렇게 random sample을 하면 가깝고 유사한 sample로 weight를 업데이트하는 것이 아니라, 서로 멀리 떨어진 sample을 가지고 학습하기 때문에 더 정확하게 학습할 수 있다.
다음으로 non stationary target 은 prediction의 네트워크를 업데이트하는 동안 target의 네트워크도 같이 변하는 문제가 있다. 이 문제를 해결하기 위해서는 먼저 separate networks를 해서 main network와 target network로 나누고, main network의 weight만 업데이트한다. 그리고 일정 시간이 지난 뒤에 main network를 target network에 copy 하면 된다.
TF 1.0 코드: github.com/hunkim/ReinforcementZeroToAll/blob/master/07_3_dqn_2015_cartpole.py
separate networks: 위의 코드와 같이 실제 DQN 코드를 구현할 때는 build network, predict, update가 있는 DQN class를 정의하고 main network와 target network 두 개를 선언하여 사용한다. build network는 input, weight, layer, loss function, optimizer 등 network의 shape를 정의하는 함수이다. predict는 state를 받아서 action을 구하는 함수이고, update는 state와 Q가 저장된 stack을 network에 넘겨주는 함수이다.
mainDQN = dqn.DQN(sess, INPUT_SIZE, OUTPUT_SIZE, name="main")
targetDQN = dqn.DQN(sess, INPUT_SIZE, OUTPUT_SIZE, name="target")
sess.run(tf.global_variables_initializer())
# initial copy q_net -> target_net
copy_ops = get_copy_var_ops(dest_scope_name="target", src_scope_name="main")
sess.run(copy_ops)
capture and replay: deque 형태의 replay buffer를 만든다. action을 수행해서 얻은 reward, next state, done을 buffer에 저장한다. 그리고 buffer가 batch size만큼 차면 random sample 하여 저장된 elements를 가지고 Y를 구한다. 실제 학습에는 X와 Y만 필요하기 때문에 X(state)와 Y(Q value)를 vertical stack에 쌓은 뒤에 DQN network에 update 한다.
states = np.vstack([x[0] for x in train_batch])
actions = np.array([x[1] for x in train_batch])
rewards = np.array([x[2] for x in train_batch])
next_states = np.vstack([x[3] for x in train_batch])
done = np.array([x[4] for x in train_batch])
X = states
Q_target = rewards + DISCOUNT_RATE * np.max(targetDQN.predict(next_states), axis=1) * ~done
y = mainDQN.predict(states)
y[np.arange(len(X)), actions] = Q_target
# Train our network using target and predicted Q values on each episode
return mainDQN.update(X, y)
이렇게 network를 분리하고, episode를 돌면서 일정 step마다 buffer를 비우면서 training을 한 뒤에는, main network만 update 한다.
replay_buffer.append((state, action, reward, next_state, done))
if len(replay_buffer) > BATCH_SIZE:
minibatch = random.sample(replay_buffer, BATCH_SIZE)
loss, _ = replay_train(mainDQN, targetDQN, minibatch)
위와 마찬가지로 어느정도 학습을 한 뒤에는 target network에 main network를 copy 한다.
if step_count % TARGET_UPDATE_FREQUENCY == 0:
sess.run(copy_ops)
tensorflow 1.0 Q net:
https://github.com/hunkim/ReinforcementZeroToAll/blob/master/06_q_net_frozenlake.py
tensorflow 2.0 DQN:
https://www.tensorflow.org/agents/tutorials/1_dqn_tutorial
'데이터 사이언스 공부 > 강화학습' 카테고리의 다른 글
| 3) Dynamic Programming, Policy Evaluation, Iteration (0) | 2020.11.12 |
|---|---|
| 2) Agent, Environment, State (0) | 2020.09.10 |
| 1) MDP, Value Function, Bellman Equation (0) | 2020.09.04 |
| 2) Q-learning exploit & exploration and discounted reward, stochastic(non-deterministic) world (0) | 2020.08.07 |
| 1) Reinforcement Learning, Open AI GYM (0) | 2020.07.29 |